
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- tomcat log
- 국세청 해외주식 양도세 신고방식
- 테스트 자동화
- 피보나치함수
- 피보나치함수 예제
- 톰캣 실시간 로그
- oracle group by
- katalon 자동화
- 홈택스 해외주식 양도세
- CSTS 폭포수 모델
- 피보나치 예제
- javascript 자동완성
- bfs 미로탐색 java
- 한국투자증권 해외주식 양도세
- katalon
- 재귀 예제
- katalon xpath
- 주식 양도세 신고방법
- 최대공약수 예제
- git 연동
- 해외주식 양도세 신고
- 한국투자증권 양도세 신고
- Katalon Recorder 사용법
- java.sql.SQLSyntaxErrorException
- recursion example
- 해외증권 양도세 한국투자증권
- js 자동완성
- katalon 비교
- 재귀함수 예제
- katalon 사용법
- Today
- Total
엄지월드
백준 1520 내리막길(DFS + DP) 본문


DFS로 풀었는데 메모리초과, 시간초과가 나길레 검색을 해보니 DP를 함께 활용하는 문제였다.
그래서 검색을 진행하였고 나온 코드를 기반으로 이해를 진행하면서, 내 코드에서 DP를 활용하도록 변경해주었다.
문제 접근 방법
- 시작 시 dp[x][y] = 0 으로 바꿔주면서 해당 경로를 방문을 했다고 친다.
- if(map[x][y] <= map[nx][ny]) continue; 를 통해서 낮은 계단만 탐색한다.
- dp[x][y] += dfs(x,y);를 통해서 탐색이 완료된 각각의 경우를 더해준다.
- 마지막으로 DFS 가장 앞에 탈출 조건을 걸어준다.
1) dp[x][y]를 이미 탐색 해서 다시 탐색할 필요가 없을 때
2) N,M에 도달했을 때
hash.add(arr[people.x][people.y]);
for(int i=0; i<4; i++){
int nx = people.x + dx[i];
int ny = people.y + dy[i];
// 범위를 벗어나면
if(nx < 0 || ny < 0 || nx >= R || ny >= C) continue;
dfs(new People(nx, ny, people.cnt+1));
}
hash.remove(arr[people.x][people.y]);헷갈렸던 점
- 처음에는 visited를 운영해서 for문 전에 visited = true, for문 후에 visited = false로 처리해서 탐색했던 길을 초기화 해주면서 모든 경로를 탐색했었는데, 시간초과가 발생했었다.
public static void dfs(int x, int y){
visited[x][y] = true;
if(x == N-1 && y == M-1){
result += 1;
visited[x][y] = false;
return;
}
for(int i=0; i<4; i++){
int nx = x + dx[i];
int ny = y + dy[i];
if(nx < 0 || ny < 0 || nx >= N || ny >= M) continue;
if(visited[nx][ny] || map[x][y] <= map[nx][ny]) continue;
dfs(nx, ny);
}
visited[x][y] = false;
}- 그렇다고 기본 DFS와 같이 visited = true로만 운영하게 되면 방문했던 곳을 다시 방문할 수가 없었다.
- 그래서 DFS 재귀가 끝나고 회수하는 과정에서 방문은 했다고 처리하면서 다음 DFS(x,y)시에는 방문하지 않은 곳부터 방문을 진행하기 위해서 DP를 활용한다.
- DP 배열을 디버깅 찍어보면 아래와 같이 1번 방문한 경로는 1로 표시되고 있고, 갈래길이라 나뉘는 곳은 1 이상으로 표시되고 있다.
- 예로 들면 2인 곳은 해당 위치에서 부터 마지막까지 가는 길까지 2가지 경로가 있다는 것으로 인지하면 된다.
return 1; 하는 부분과 dp[x][y] += dfs(nx,ny);로 처리되는 부분이다.
마지막 문장을 다시 말해보면
- 가장 마지막에 1로 되어 있는 이유는 아래 코드
if(x == N-1 && y == M-1){
return 1;
}- 1 초과로 되어 있는 이유는 dfs 재귀가 끝나면서 dp[x][y]에 더해준다.
dp[x][y] += dfs(nx, ny);- 그래서 dfs(0, 0)에 있는 값을 출력해주면 정답이다.
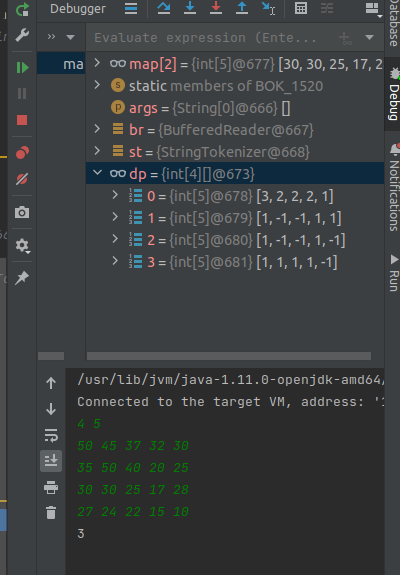
전체 코드
package Baekjoon;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class BOK_1520 {
static int N;
static int M;
static boolean visited[][];
static int[][] map;
static int [] dx;
static int [] dy;
static int[][] dp;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
N = Integer.parseInt(st.nextToken());
M = Integer.parseInt(st.nextToken());
visited = new boolean[N][M];
map = new int[N][M];
dp = new int[N][M];
dx = new int[]{-1 ,1, 0, 0};
dy = new int[]{0, 0, -1, 1};
for(int i=0; i<N; i++){
st = new StringTokenizer(br.readLine());
for (int j = 0; j < M; j++) {
map[i][j] = Integer.parseInt(st.nextToken());
}
}
for(int i=0; i<N; i++){
for (int j = 0; j < M; j++) {
dp[i][j] = -1;
}
}
System.out.println(dfs(0, 0));
System.out.println(dp);
}
public static int dfs(int x, int y){
if(x == N-1 && y == M-1){
return 1;
}
// -1이 아닌 경우는 이미 방문한 경우(메모이제이션)
if(dp[x][y] != -1) return dp[x][y];
dp[x][y] = 0;
for(int i=0; i<4; i++){
int nx = x + dx[i];
int ny = y + dy[i];
if(nx < 0 || ny < 0 || nx >= N || ny >= M) continue;
if( map[x][y] <= map[nx][ny]) continue;
dp[x][y] += dfs(nx, ny);
}
return dp[x][y];
}
}'알고리즘' 카테고리의 다른 글
| 오픈채팅방 java (0) | 2022.09.03 |
|---|---|
| 백준 2573 빙산(DFS+BFS) (0) | 2022.08.31 |
| 백준 2583 영역 구하기 (0) | 2022.08.28 |
| 42579 (해시) (2) | 2022.08.27 |
| 백준 11725 트리의 부모 찾기(DFS) (0) | 2022.08.26 |

