
- 전체 글 (407)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 피보나치함수 예제
- oracle group by
- java.sql.SQLSyntaxErrorException
- 톰캣 실시간 로그
- bfs 미로탐색 java
- 최대공약수 예제
- 피보나치 예제
- 해외주식 양도세 신고
- javascript 자동완성
- tomcat log
- 국세청 해외주식 양도세 신고방식
- Katalon Recorder 사용법
- 재귀함수 예제
- 해외증권 양도세 한국투자증권
- katalon 자동화
- 피보나치함수
- 한국투자증권 해외주식 양도세
- 테스트 자동화
- recursion example
- CSTS 폭포수 모델
- git 연동
- js 자동완성
- 홈택스 해외주식 양도세
- 한국투자증권 양도세 신고
- katalon 비교
- katalon xpath
- katalon 사용법
- 재귀 예제
- 주식 양도세 신고방법
- katalon
- Today
- Total
엄지월드
[1차시] 머신러닝 기초 개념 / Google Colab 소개 본문
인공지능(Artificial Intelligence) : 컴퓨터가 인간과 같이 생각할 수 있도록 만드는 기법을 연구하는 학문
머신러닝(Machine Learning) : 데이터에 기반한 학습을 통해 인공지능을 구현하는 기법들을 지칭.
딥러닝(Deep Learning) : 머신러닝 기법 중 하나인 인공신경망(Artificial Neural Networks) 기법의 은닉층(Hidden Layer)을 깊게 쌓은 구조를 이용해 학습하는 기법
머신러닝 : 명시적인 프로그래밍 없이 데이터를 이용해서 예측 또는 분류를 수행하는 알고리즘을 구현하는 기법을 뜻함.
머신러닝은 한국말로 기계 학습이라고도 부름.
머신러닝이 필요한 이유
- 머신러닝 방법론을 이용할 경우, 인간이 정확히 하나하나 로직을 지정 해주기 어려운 복잡한 문제를 데이터에 기반한 학습을 통해서 해결할 수 있습니다.
e.g.) 어떤 사용자에게 어떤 광고를 보여주는 것이 최적의 광고 배분 전략일까?
- 머신러닝 알고리즘을 사용할 때 가장 중요한 부분은 머신러닝 모델이 잘 학습할 수 있또록 적절한 특징(Feature)을 설정해주는 것 입니다.
머신러닝 알고리즘의 3가지 분류

지도 학습(Supervised Learning)
- 지도학습은 정답 데이터가 존재하는 상황에서 학습하는 알고리즘입니다. 좀 더 엄밀하게 정의하면 입력 데이터 x와 그에 대한 정답 레이블 Label y의 쌍Pair (x,y)를 이용해서 학습하는 알고리즘입니다.
- 예를 들어, 그림 1-5와 같은 28x28 크기의 이미지인 MINIST 데이터셋이 있으면 이를 이용해 학습을 진행할 때, 지도 학습의 트레이닝 데이터셋은 다음과 같이 구성될 것입니다.
- 대부분의 문제들을 해결함. 나머지는 제한적이고, 연구중임.

비지도 학습
- 정답 레이블 y 없이 입력 데이터 x만을 이용해서 학습하는 알고리즘입니다. 즉, 입력 데이터 (x) 형태로 학습을 진행합니다.
- 비지도 학습은 지도 학습과 목적이 조금 다릅니다. 지도 학습의 목적이 어떤 값에 대한 예측을 수행하는 것이라면 비지도 학습은 데이터의 숨겨진 특징(Hidden Feature)을 찾아내는 것에 목적이 있습니다.
- 예를 들어, 그림 1-6을 보면 왼쪽 그림처럼 데이터가 무작위로 분포되어 있을 때, 비지도 학습의 일종인 클러스터링 알고리즘을 이용하면 오른쪽 그림과 같이 비슷한 데이터들끼리 3개의 그룹으로 묶을 수 있습니다.

강화 학습
- 지도 학습과 비지도 학습과는 학습하는 방법이 조금 다른 기법입니다.
- 앞서 살펴본 데이터가 이미 주어진 정적인 상태에서 학습을 진행했다면, 강화 학습은 에이전트가 주어진 환경에서 어떤 행동을 취하고 이에 대한 보상을 얻으면서 학습을 진행합니다.
- 강화학습은 동적인 상태에서 데이터를 수집하는 과정까지 학습 과정에 포함되어 있는 알고리즘입니다.

지도 학습(Supervised Learning)
- 머신러닝 모델은 일반적으로 지도 학습(Supervised Learning)이라는 방법론을 사용합니다.
- 지도 학습 방법론을 사용하기 위해서는 트레이닝 데이터의 구성이 (인풋 데이터, 데이터에 대한 정답) 쌍으로 구성되어 있어야만 합니다.
즉, 지도 학습은 정답을 보여주면서 학습시키는 머신러닝 방법론입니다.
- 이때 보통 인풋 데이터를 x, 데이터에 대한 정답을 y라고 부릅니다.
- 예를 들어, 우리가 키를 기반으로 몸무게를 예측하는 모델을 만드는 경우를 생각해보면 트레이닝 데이터는 여러 사람에게서 수집한 키와 몸무게 데이터가 됩니다.

- 이런 식으로 (x,y)로 구성된 데이터를 학습용 데이터라고 부릅니다.
머신러닝 모델을 사용하는 경우 다음의 2가지 과정을 거칩니다.
1) 학습용 데이터로 머신러닝 모델을 학습시킵니다.
2) 학습된 머신러닝 모델의 성능을 트레이닝 데이터에 포함되어 있지 않고 따로 뺴놓은 테스트 데이로 측정합니다.

트레이닝 데이터, 테스트 데이터 나누기(split)
- 따라서 머신러닝 모델을 학습시키기 위해서 전체 데이터의 일부를 Training Data, 일부는 Test Data로 나눠서 사용합니다.
- 일반적으로 데이터의 80% 정도는 트레이닝 데이터, 20%정도는 테스트 데이터로 나눠서 사용합니다.
- 예를 들어 1000명의 (키, 몸무게) 데이터가 있다면 800명분의 데이터는 트레이닝 데이터, 200명분의 데이터는 테스트 데이터로 나눠서 사용합니다.
Validation Data(검증용 데이터)
- 여기에 더 나아가서 전체 데이터를 트레이닝 데이터, 검증용 데이터, 테스트 데이터로 나누기도 합니다.
- 검증용 데이터는 트레이닝 과정에서 학습에 사용하지는 않지만 중간중간 테스트하는데 사용해서 학습하고 있는 모델이 오버피팅에 빠지지 않았는지 체크하는데 사용됩니다.
Overfitting, Underfitting
- 처음에는 트레이닝 에러와 검증 에러가 모두 작아지지만 일정 횟수 이상 반복할 경우 트레이닝 에러는 작아지지만 검증 에러는 커지는 오버피팅에 빠지게 됩니다.
- 따라서 트레이닝 에러는 작아지지만 검증 에러는 커지는 지점에서 업데이트를 중지하면 최적의 파라미터를 얻을 수 있습니다.
-> Early stopping을 통해 사전에 stop하는 것도 중요하다.



분류(Classification) 문제, 회귀(Regression) 문제
분류문제 : 예측하는 결과값이 이산값인 문제
e.g. 이 이미지에 해당하는 숫자는 1인가 2인가?
회귀문제 : 예측하는 결과값이 연속값인 문제
e.g. 3개월 뒤의 아파트 가격은 2억 1천만원일 것인가? 2억 2천만원일 것인가?
머신러닝을 구현하기 위한 대표 라이브러리들 - Numpy, Pandas, scikit-learn
Numpy, Pandas : 머신러닝에 필요한 데이터를 불러오고 전처리하기 위해 사용
scikit-learn : 머신러닝 알고리즘을 구현하기 위해 사용
Google Colab 소개
Google Colaboratory 줄여서 colab 이라고도 부르는 서비스는 Google에서 데이터 과학자와 연구자를 위한 공개한 서비스입니다.
Colab을 사용할 경우 다음과 같은 장점이 있습니다.
- 구성이 필요하지 않음
- GPU 무료 액세스
- 간편한 공유

numpy -> 배열을 다루는 도구
Numerial python : 다차원배열을 쉽게 처리할 수 있게 도와주는 패키지.
다차원 배열, 행렬의 생성과 연산, 정렬 등 편리한 기능을 많이 포함하고 있음.
C언어로 이루어져 있어서 빠름.
배열의 모양보기
. shape을 이용해서 배열의 모양을 확인할 수 있습니다.
초기화 함수로 넘파이 배열 생성
z1 = np.zeros([4])
o2 = np.ones([3,4]) # 1로 채운 배열 만들기
r2 = np.random.randn(2,3) # 랜덤한 숫자 만들기
np.random.randn(2,2,4,5).round(3) # 무척 큰 4차원 배열 만들기






pandas -> 데이터 표를 다루는 도구
pandas의 등장. 데이터에 라벨을 붙이고 싶어요.
pandas 기본 1. Series 행x값 데이터
- 데이터 배열에 이름과 각 데이터의 라벨(인덱스)를 붙임.


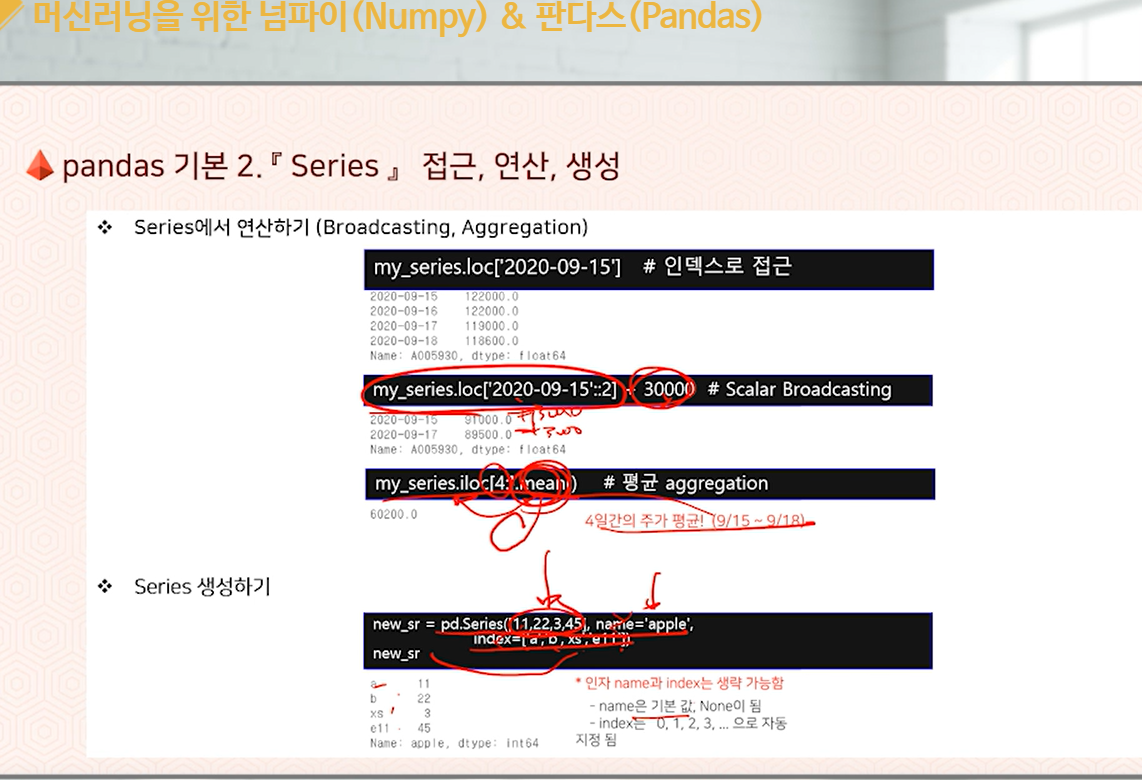





- 넘파이(Numpy) 라이브러리는 "Numerical Python"의 약자 다차원 데이터를 쉽게 처리할 수 있게 도와주는 패키지로 다차원 배열, 행렬의 생성과 연산, 정렬 등 편리한 기능들을 많이 포함하고 있습니다.
- 판다스(Pandas)는 행과 열을 가진 데이터를 쉽게 다룰 수 있도록 도와주는 라이브러리로 Series와 DataFrame 객체를 지원합니다.
- 넘파이 배열과 판다스 객체에서 Indexing과 Slicing을 이용해서 일부 요소값을 추출할 수 있습니다.
- 넘파이 배열과 판다스 객체에서 Aggregation 연산을 통해서 원하는 값들을 계산할 수 있습니다.
'기타' 카테고리의 다른 글
| [2차시] 애플리케이션 구동 시간 단축하기 : 빠른 스타트업을 위한 전략과 기법 (2) | 2025.03.17 |
|---|---|
| [1차시] 스프링 부트 성능 최적화 전략 : 기본 개념부터 핵심 원칙까지 (0) | 2025.03.17 |
| TOPCIT 연습하기 모의응시 문제풀이(2017) (0) | 2023.10.27 |
| [제로베이스 백엔드스쿨] 7월 수강후기 (2) | 2022.07.29 |
| [제로베이스 백엔드스쿨] 6월 수강후기 (0) | 2022.06.28 |
