알고리즘
백준 1920 수 찾기
킨글
2024. 4. 15. 20:53
문제
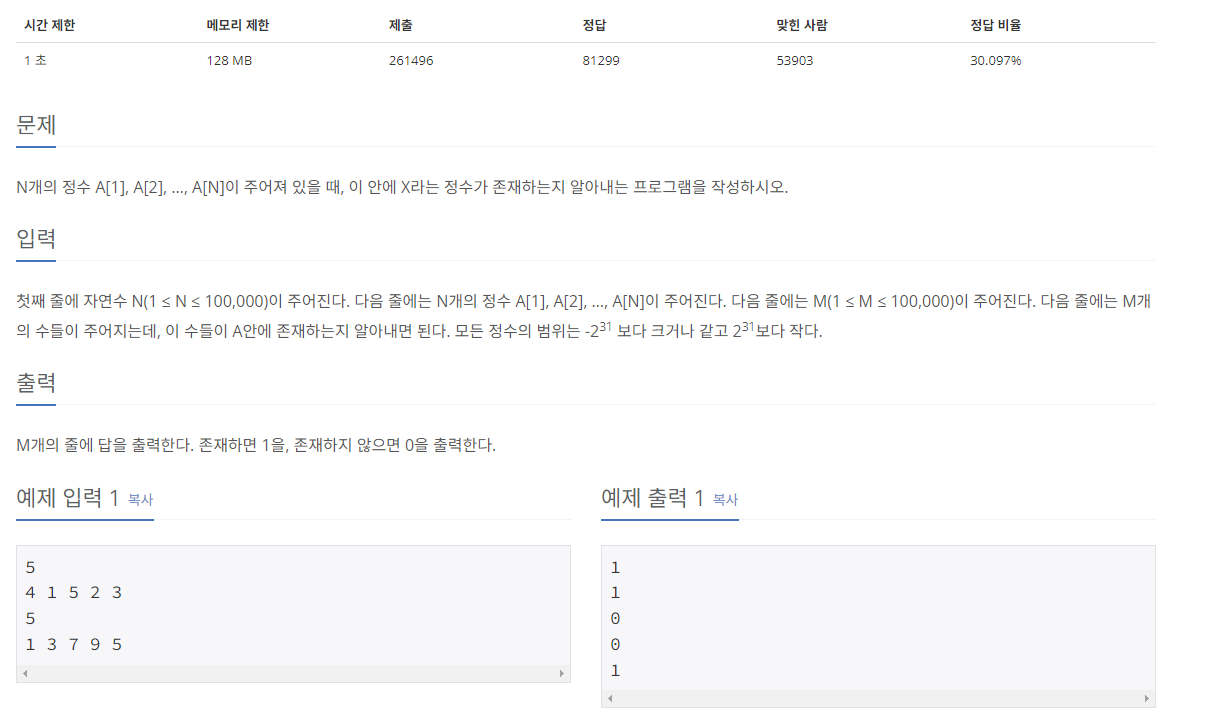
방법
정답률이 30%여서 시간초과 걱정을 했다.
그래서 빠른 방법을 고민했고, O(N) 속도인 Set을 쓰고 Set에서도 Integer가 아닌 String으로 바로 비교했다.
Set<Integer>와 Set<String>간의 속도 차이가 있을까? 궁금해서 gpt에게 물어봤지만 차이가 없다고 답변이 왔다.
그래서 set.add(Integer.parseInt(st.nextToken)); 부분에서 Integer.parseInt라도 줄여보기 위해 Set<String>을 사용했다.
그리고 나서 Set<Integer>의 속도가 궁금해서 Integer로 바꾸고 Integer.parseInt(st.nextToken)) 으로 바꿔서 해보았는데,
아래와 같이 540ms과 604ms가 나왔다. 결론적으로는 별 차이 없었다.

코드
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.HashSet;
import java.util.Set;
import java.util.StringTokenizer;
public class Main {
// 1920
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
Set<String> set = new HashSet<>();
int N = Integer.parseInt(br.readLine());
StringTokenizer st = new StringTokenizer(br.readLine());
for (int i = 0; i < N; i++) {
set.add(st.nextToken());
}
int M = Integer.parseInt(br.readLine());
st = new StringTokenizer(br.readLine());
for (int i = 0; i < M; i++) {
if (set.contains(st.nextToken())) {
bw.write("1\n");
} else {
bw.write("0\n");
}
}
bw.flush();
bw.close();
}
}